
(对应视频发布在抖音号上)
引言
现如今,村口大妈聊天张口就是大语言模型,就连小学生都知道用 DeepSeek 来查作业。但是,却很少有人真正理解它们到底是如何工作的。这个视频我们一起来揭开大语言模型运作的基本原理,看它如何从“笨小孩”变成“天才”!放心,这篇文章不会涉及复杂的数学知识,我只会用村口大妈和小学生都能听懂的文字来讲解。准备好了吗?让我们一起进入这个神奇的 AI 世界!
人类与电脑的语言理解
在理解大语言模型如何理解文字之前,我们先来看看人类是如何理解文字的。

想象一下,当你读到“猫在沙发上睡着了”,脑海里立刻浮现一只慵懒的猫,蜷在软乎乎的沙发上。你不仅懂了字面,还能感觉到画面,甚至猜到猫可能很舒服。这是为什么?因为人类理解文字不只是看字面,而是靠经验、语境和对世界的认知。
人类理解文字这么自然,但对电脑来说却是个大难题。电脑不像我们有生活经验,也不会自动“脑补”画面。早期,电脑把“猫”和“狗”当完全无关的符号,处理语言就像死记硬背字典,效率低还容易出错。那如何让电脑像人一样,抓住词的含义、语境,甚至是推理呢?
Word2Vec:词向量的革命
2013 年,谷歌公司为了提升搜索引擎和语言处理工具的性能(比如当用户搜索“国王”时,能知道它和“女王”有关,而不是和“工人”有关),研究了神经网络语言模型(NNLM)。但 NNLM 计算复杂,训练需要大量时间和算力。

于是,几位研究员——托马斯·米科洛夫(Tomas Mikolov)、陈凯(Kai Chen)、格雷格·科拉多(Greg Corrado)、杰夫·迪恩(Jeff Dean)——想到:能不能让电脑通过分析海量文本,自动学会词的含义和关系?他们在论文《Efficient Estimation of Word Representations in Vector Space》中提出了一项划时代的技术 Word2Vec,并开源了代码。
Word2Vec 是一种把单词变成计算机能理解的词向量(Word Vectors)的方法,目标是让计算机知道单词之间的关系,比如“猫”和“狗”意思上有点像,但“猫”和“桌子”差别就很大。
什么是词向量?
举个例子,华盛顿特区位于北纬 38.9 度,西经 77 度,我们可以用向量表示:[38.9, 77]。
纽约的位置用向量表示为 [40.7, 74],
巴黎为 [48.9, -2.4]。从这些向量坐标你能看出华盛顿特区离纽约很近,但离巴黎很远。词向量也采用了类似的方法,赋予每个词向量空间的概念,含义相近的单词在向量空间中靠得更近。
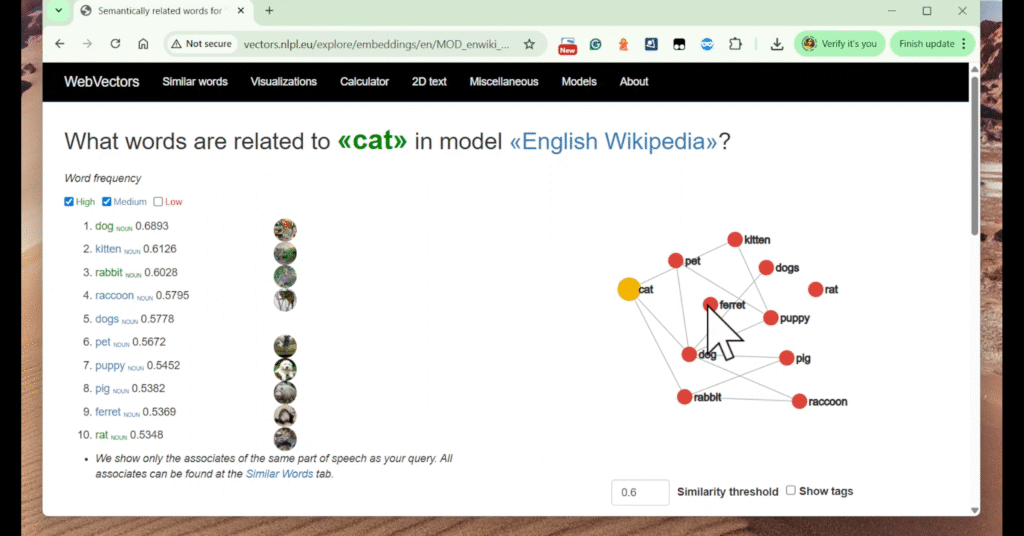
例如,在向量空间中,离“cat”最近的单词包括“dog”和“pet”。
然而,人类语言中的文字非常复杂,不仅要表达它们的相似性,还要表达颜色、品种、大小、食物习性、叫声、行走方式等。因此,仅用一个二维空间坐标来表示是远远不够的,语言模型中使用的词向量往往需要成千上万维的向量空间。人脑无法想象如此高维的空间,但计算机完全能够处理成千上万维度的词向量并产生有用的结果。
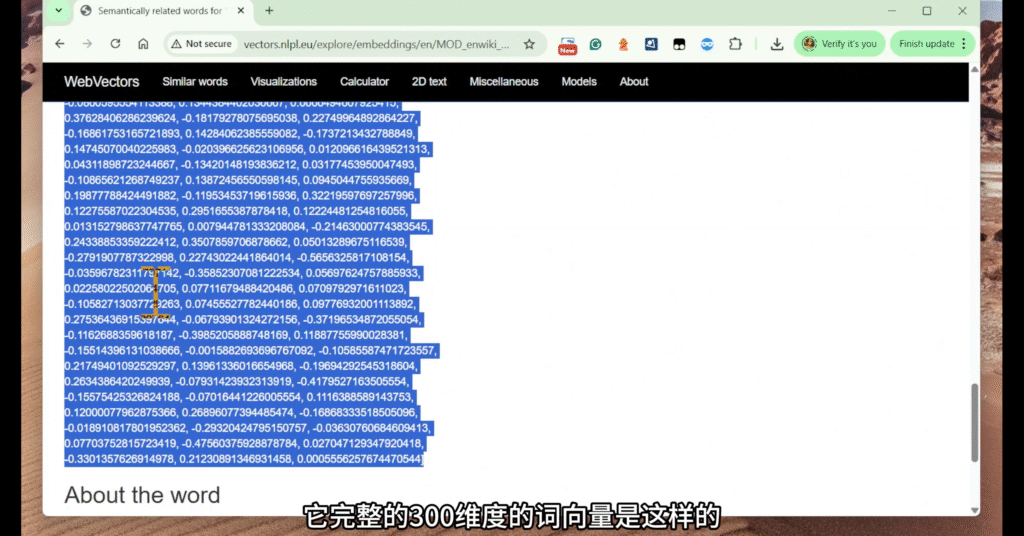
例如,cat 的 300 维词向量 显示,离“cat”最近的词是“dog”、“kitten”、“rabbit”。是不是感到词向量真是一个天才的设计呢?
词向量的推理能力
词向量还有一个有趣的特性:你可以通过向量运算来“推理”单词。例如,谷歌研究人员用“biggest”的向量减去“big”,再加上“small”,结果离得最接近的单词就是“smallest”(“biggest – big + small ≈ smallest”)。看到了吗,词向量可以通过简单的向量运算实现复杂的语义推理,这已经很类似于人类的类比能力。
谷歌公司的 Word2Vec 像一颗耀眼的流星,照亮了 NLP 的天空,也是 NLP 发展的里程碑。Word2Vec 的向量表示和上下文学习思想,直接影响了 Transformer 和大型语言模型(如 GPT-3),成为 AI 发展的基石。
Transformer:上下文的突破
不过,研究人员很快发现,单词往往具有多种含义。例如,“风”字在“今天外面刮了大风”中指自然界的空气流动,而在“这幅画很有传统中国风”中指某种艺术或文化的风格。显然,虽然是同一个“风”字,但它们的含义不同,因此应该使用不同的词向量来表示。
又比如,“小明请师傅修他的车”中,“他的车”到底是谁的?是小明的还是师傅的?根据常识,人类能很容易理解是师傅帮车主小明修车,但如果没有明确的上下文语境,计算机就很难确定。
于是在 2017 年,Google Brain 团队在 NIPS(神经信息处理系统大会)上发表论文《Attention is All You Need》(论文链接),提出了 Transformer 技术。Transformer 的核心功能是处理词向量序列,通过自注意力机制和前馈网络生成上下文相关的表示,解决多义性和指代模糊等问题。
Transformer 的工作原理
就像“风”这样的词,单独看可能有好几种意思。但 Transformer 会看整句话,比如通过观察“刮了一阵大风”里的“刮”和“大”,就知道“风”是自然界的风;而在“中国风”里,它会看“中国”“传统”等词,明白“风”只是一种艺术风格。又比如,在“小明请师傅修他的车”中,Transformer 会分析整句话,发现“小明”是主语,通常是他在请人修车,所以要修的车更可能是小明的。
具体来说,Transformer 通过引入一种叫“注意力机制”的方法,重点关注句子中相关的词,从而像人一样“思考”上下文。当大语言模型拿到一段文本资料后,分词器会将文本拆成小块(也叫“词”或“子词”),如 [“今”, “天”, “的”, “风”, “真”, “大”, “。”],也就是我们常说的 token。然后,嵌入层(Embedding Layer)中有一个词汇表,每个词会对应一个向量,嵌入层通过查表将每个字符(比如“风”)变成一个初始词向量,比如一个 12,288 维的词向量 [0.23, -0.45, …, 0.12]。
由于 Transformer 的自注意力机制不具备 RNN 的序列处理能力,这些词向量还会被添加位置编码(Positional Encoding)来保留词的顺序信息。位置编码与词向量相加,形成 Transformer 的输入数据。
Transformer 的多层分析
紧接着,这些词向量会被送入 Transformer 架构中。
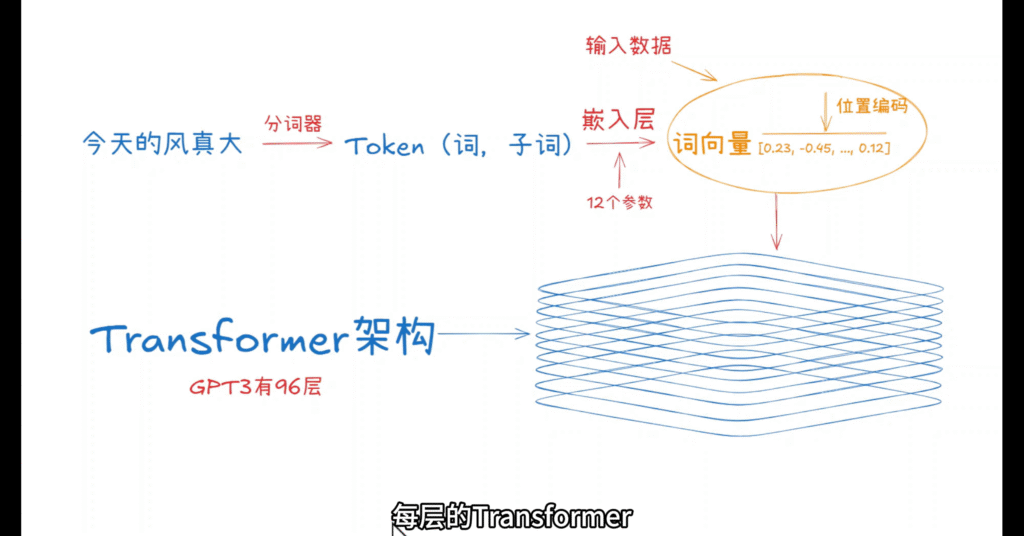
Transformer 会分析句子中每个字符和其他字符的关系来理解句子的整体意思。Transformer 通常会有多层(像 GPT-3 就有 96 层),每层像一个“分析滤网”,逐层处理这些词向量,逐步提炼句子的上下文信息。例如:
- 第 1 层可能关注简单的语法(比如“的”是修饰词)。
- 第 10 层可能关注更复杂的句法关系(比如“今天的”修饰“风”)。
- 第 96 层可能捕捉高层次语义(比如“风真大”表示强烈的天气现象)。
每层 Transformer 包含两个主要子模块:自注意力机制层和前馈神经网络层。它们有不同的职责:
- 自注意力机制:在“今天的风真大”中,处理“风”时,自注意力会关注“的”“真”“大”,因为这些字符帮助确定“风”是自然风。
- 前馈神经网络(Feed-Forward Neural Network, FFN):接收来自注意力机制的词向量,对每个词向量进行进一步加工,提取更复杂的语义特征,增强模型的表达能力。例如,自注意力机制已经让“风”的表示包含了上下文(比如“真大”这样的信息),前馈神经网络再对这个表示进行“深加工”,提取更抽象的特征,比如“风真大”可能暗示“天气不好”或“需要注意安全”。
前馈神经网络的细节
前馈层本身是一个小型神经网络,内部由多层神经元组成,
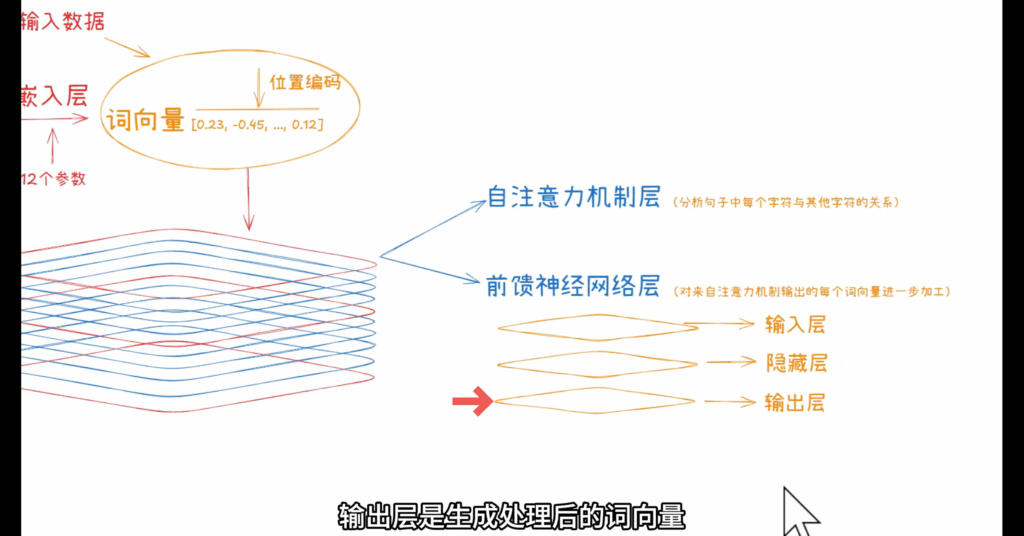
通常包括输入层、隐藏层、输出层:
- 输入层:接收来自注意力机制的词向量(在 GPT-3 中是 12,288 维)。
- 隐藏层:是一个中间处理层,包含大量神经元(GPT-3 有 49,152 个),进行复杂的模式匹配。
- 输出层:生成处理后的词向量(GPT-3 仍是 12,288 维),传递到下一层 Transformer。
前馈层的强大之处在于其庞大的连接数量。在 GPT-3 中,隐藏层有 49,152 个神经元,每个神经元有 12,288 个输入;输出层有 12,288 个神经元,每个神经元有 49,152 个输入值。这意味着每个前馈层有 49,152 × 12,288 + 12,288 × 49,152 = 12 亿个权重参数。而 GPT-3 有 96 个前馈层,总计 12 亿 × 96 = 1160 亿个参数!在前馈层中,参数数量几乎占 GPT-3 总计 1750 亿个参数的三分之二。
参数的构成
你可能听过某个大模型有多少亿个参数,没错,就是这些参数。例如,在 GPT-3 中:
- 前馈层:约 1160 亿个参数。
- 嵌入层:约 12 亿个参数(每个词向量有 12,288 个维度,大约有 10 万个词汇)。
- 自注意力层:约 576 亿参数(查询、键、值矩阵:3 × 12,288 × 12,288 = 4.5 亿(每层);输出投影矩阵:12,288 × 12,288 = 1.5 亿(每层);每层约 6 亿参数,96 层共约 576 亿参数)。
- 层归一化:少量参数。
总计约 1750 亿参数。
自监督学习:从“笨小孩”到“语言天才”
当所有 Transformer 层分析完句子后,这些词向量包含非常丰富的上下文信息,模型框架会用这些处理后的词向量进行训练任务,从而让它学会预测。
在早期的机器学习算法中,需要人类手动标注训练样本。例如,训练数据可能是狗或猫的照片,每张照片由人类标注为“狗”或“猫”。这种人工标注数据的需求使得训练大模型变得困难且昂贵。而大语言模型(LLMs)的一个关键创新是不再需要明确标注的数据,它们采用自监督学习机制(Self-supervised Learning)进行学习。
自监督学习的“猜字游戏”
大语言模型的训练方式非常简单。训练程序从现成的文本数据(如维基百科、书籍)中提取完整的句子,然后自动截断这个句子使它成为不完整句子,再去猜下一个词应该是什么。简单说,就是玩一个“猜字游戏”。具体分为两步:前向传播和反向传播。

假设训练数据中有这样一句话:“我喜欢喝咖啡加奶油和糖”。训练程序会截断成:“我喜欢喝咖啡加奶油和__”,然后让模型预测下一个词是什么。这一步就是前向传播(Forward Propagation)。
最开始,模型完全不懂语言,所有参数都是随机的,就像一个刚出生的婴儿,猜词全靠蒙。因此,它可能会猜是“盐”,明显不对。于是,模型会“回头看”整个计算过程,找出哪些权重导致了错误,然后稍微调整这些权重参数,这就是反向传播(Back Propagation)。
需要注意的是,训练目标是学会整个语言的规律(语法、语义、常识),而不是让某个特定句子(“我喜欢喝咖啡加奶油和糖”)的预测完美无误。因此,针对“我喜欢喝咖啡加奶油和__”这个句子,在经历一次前向传播和一次反向传播后,模型只是稍微学会一点点规律,可能只知道“和”后面可能需要接一个词。
想要猜得更准确,模型需要训练几十上百亿的句子。每次迭代,模型会看到不同句子(比如“我喜欢喝茶加柠檬和糖”“她爱吃面包加黄油和果酱”),通过这些句子学会“和”后面接名词的通用规律。在积累训练迭代后,大模型才能预测出“我喜欢喝咖啡加奶油和__”后边填“糖”是最合适的。这就是模型的自监督学习机制。
训练的计算量
训练语言模型是个超级大的工程!例如,GPT-3 总共有 1750 亿个参数,每次猜词需要对 1750 亿个权重做数学运算。GPT-3 需要训练数百亿个句子,每猜一个词就得做一次前向传播和反向传播,因此初步估计 OpenAI 训练 GPT-3 需要进行 3000 亿万亿次浮点运算。这是一个非常巨大的计算量,所幸现代电脑已经很强大,才能处理这么大的计算量。
大语言模型的使用
训练好的大型语言模型是一个已经“读了几十亿本书”的“超级大脑”,就可以投入使用了。在使用中,当用户输入一个问题时,大模型仍然会用分词器先进行分词,然后嵌入层将词映射为词向量,再经过 Transformer 推理后采用自回归逐词生成回复,在真正输出给用户之前,可能还会进行自然语言的整理。
大模型的“黑箱”本质
大模型像一个超级复杂的“黑箱”,基于 Transformer 架构,使用非线性运算,在海量数据上通过自监督学习,经历数十亿次迭代,每次迭代调整微小参数,在积累无数微小变化后,才最终形成模型的“知识”。但人类大脑只擅长理解线性、简单的因果关系,大模型的参数交互是非线性的高维,已经超出了人类直观认知的能力。因此,到目前为止,地球上没有一个人能完全理解大型语言模型的内部运作机制。即使是开发大型语言模型的工程师(比如 OpenAI、Google 的工程师),他们虽然理解模型的整体架构和设计原理,但也无法完全理解模型的内部机制。
参考文献
- Large language models, explained with a minimum of math and jargon
- Efficient Estimation of Word Representations in Vector Space
- word2vec Parameter Learning Explained
- Attention is All You Need
- Improving Language Understanding by Generative Pre-Training
- Language Models are Few-Shot Learners
- GPT-4 Technical Report
- Scaling Laws for Neural Language Models
- Evaluating Large Language Models in Theory of Mind Tasks
- Sparks of Artificial General Intelligence: Early experiments with GPT-4
- INTERPRETABILITY IN THE WILD: A CIRCUIT FOR INDIRECT OBJECT IDENTIFICATION IN GPT-2 SMALL
