
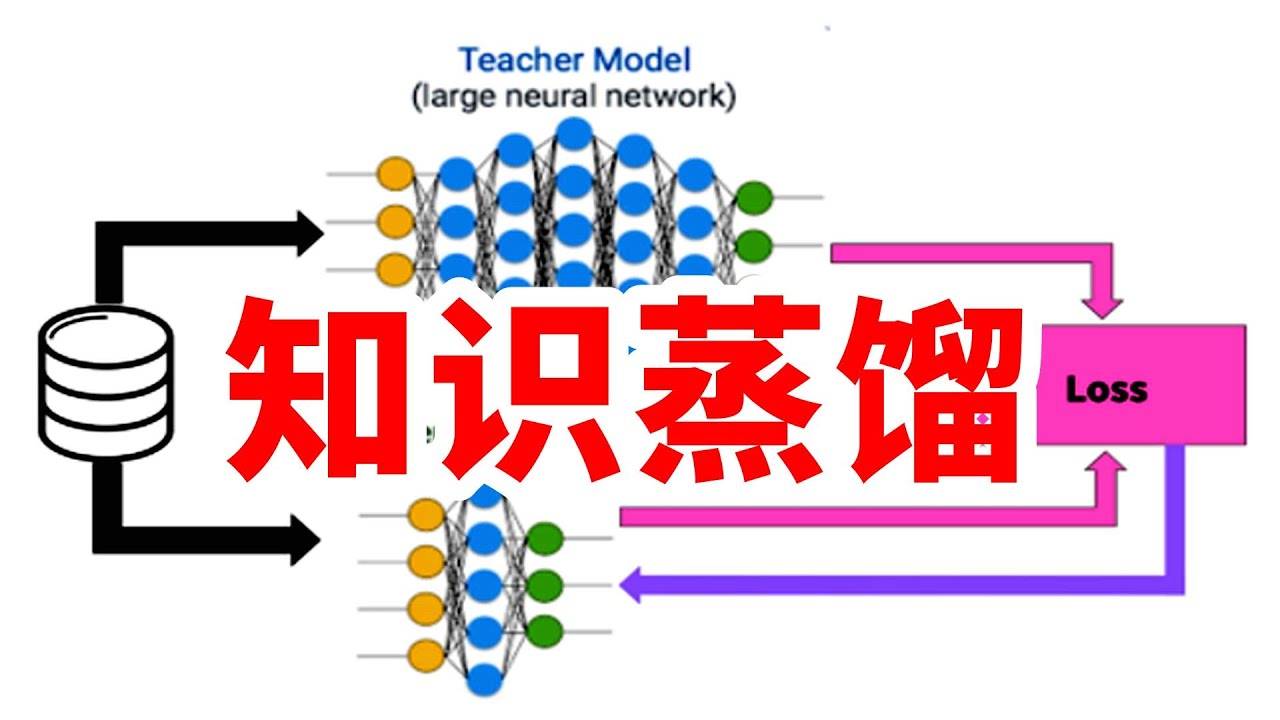
什么是大模型知识蒸馏:
知识蒸馏听起来高大上,其实就是AI版的“师徒传承”。老师模型不只告诉你正确答案,还分享它对每个选项的‘信心’。学生模型通过模仿老师模型的‘思考方式’,能用更少数据学到更强的泛化能力。
那为什么要进行知识蒸馏
首先当然是从成本考虑,
根据OpenAI CEO Sam Altman亲口爆料,训练GPT-4的总成本超过1亿美元 (Sam Altman stated that the cost of training GPT-4 was more than $100 million.)
https://www.wired.com/story/openai-ceo-sam-altman-the-age-of-giant-ai-models-is-already-over/
其次当然是是在节省成本的基础上又能使学生模型的准确度非常接近老师模型
那要如何进行大语言模型的知识蒸馏呢
首先你要明白老师模型是如何学习的,在自回归生成式模型(Autoregressive LLMs)中,典型代表例如GPT系列的大模型。它们采用从左到右“滚雪球”式预测下一个词,也就是输入前文,输出下一个token,然后把输出加到输入里,继续预测下一个词。
以语料:今天天气真好 为例,模型遮住“好”字,然后来猜下一个字应该填什么,刚开始,模型什么也不会,它可能猜是“高”,但正确答案是“好”,模型发现猜错了,它会回过头去看一下哪些参数导至了偏差
然后轻微的调整一下参数,再继续猜往下猜。经过海量的训练之后,老师模型最终学会:今天天气真 后边填“好”是最合适的
知识蒸馏按照同样的规则,但是他会借助老师模型来训练自己
同样以训练语料:今天天气真好 为例 ,学生模型开始训练的时候,将“好”字遮住,变成:今天天气真_,然后让老师模型来猜下一个词是什么
老师模型见多识广,玩起这种游戏来轻而易举,它能很轻松且准确的输出预测词的软概率。得出下一个词是“好”字的概率是80%、是“冷”字的概率是15%、“不错”4%、“晴朗”1% 等这些概率分布。
学生模型也会用相同的输入进行预测,同样也输出自己计算出来的概率,分别是:”可以” 50% (0.5), “好” 10% (0.1), “不错” 20%
然后学生模型会使用 KL 散度(Kullback-Leibler Divergence)(也叫相对熵)来衡量老师模型输出的概率和学生模型输出的概率值的差异,从而得到损失值
计算 出损失值 后,学生模型同样会进行反向传播,使用优化器(如Adam)更新自己的参数,
之后学生模型会继续向后预测
最终让学生模型逐渐接近老师模型的分布的同时,模型参数量减少40-60%或更多,大大节省了成本
关于知识蒸馏,有人说“这是创新,提升AI普惠”;但也有人担忧可能触及“知识产权红线“,你怎么认为呢?
